Last reviewed and updated: 10 August 2020
We’ve been running our new and improved Developing File System Minifilters for Windows seminar for some time now. And this means that I’ve spent a considerable amount of time musing about Windows file systems, file system filters, and the Filter Manager framework. While this isn’t exactly unusual, recently my thoughts have revolved around answering a deceivingly difficult question: What does somebody really need to know to be able to write File System Minifilters these days.
To answer this question, I decided that the beginning was the best place to start. What is a Windows file system filter, anyway? How does it fit into the overall Windows I/O Subsystem architecture? Plus, Filter Manager wasn’t even released until the Windows Vista/XP SP2 timeframe. Why? Clearly folks were writing file system filters before Filter Manager existed. What provided sufficient motivation to create a whole new model? What problems does this new model solve? And, more importantly, what problems does it not solve?
So… Let’s start at the beginning
Windows I/O Subsystem Architecture
In Windows, we use a layered, packet based I/O model. Each I/O request is represented by a unique I/O Request Packet (IRP), which is sufficient to fully describe any I/O request in the system. I/O requests are initially presented to the top of a Device Stack, which is a set of attached Device Objects. The I/O requests then flow down the Device Stack, being passed from driver to driver until the I/O request is completed.
If the I/O request reaches the bottom of a Device Stack, the driver at the bottom may choose to pass the request on to the top of another Device Stack. For example, if an application attempts to read data from a file, the I/O request is initially presented to the top of the file system stack. If the request reaches the bottom of the file system stack, the I/O request may then be passed on to the top of the volume stack. At the bottom of the volume stack, the I/O request may then be passed on to the top of the disk stack. At the bottom of the disk stack, the I/O request may then be passed on to the top of the storage adapter stack.
Figure 1 is a representation of this processing if all these Device Stacks had a single Device Object.
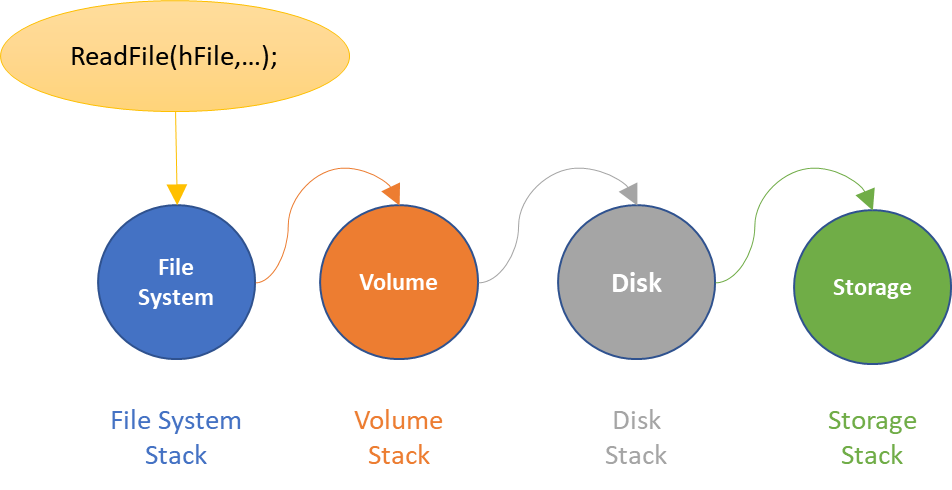
An important thing to note is that the I/O requests are passed using a call through model. This means that, using Figure 1 as our example, the File System (NTFS, for example) passes the request along by calling directly into the Volume driver. The Volume driver then directly calls into the Disk driver. The Disk driver then passes the request by calling directly into the Storage Adapter driver. Depending on the number of Device Objects and number of Device Stacks involved, this can create significantly long call chains (as we’ll see in a moment).
An awesome feature of the I/O Manager in Windows is that each individual Device Stack may contain one or more filter Device Objects. By attaching a filter Device Object to a Device Stack, a filter driver writer can intercept I/O requests as they pass through the Device Stack. A filter in the file system stack can intercept file level operations before (“pre-“) the file system driver has a chance to process them. Similarly, a filter in the volume stack would intercept volume level operations before the volume driver has a chance to process them.
Filter drivers can also intercept I/O requests after (“post-“) all lower drivers that handle the request have completed their processing. For example, using “post” processing a file system filter driver could intercept the actual data that’s been read from a file (and not just the request to read that data, that it would see as part of “pre” processing). In the “post” processing case, the file system filter would be called only after the drivers below it in the file system Device Stack and the drivers in any other Device Stacks that handle the request have all finished their processing.
Windows ships with many filter drivers in these and related stacks. Figure 2 shows a complete picture of the filters provided with a clean Windows 10 1703 (Redstone 2) installation.
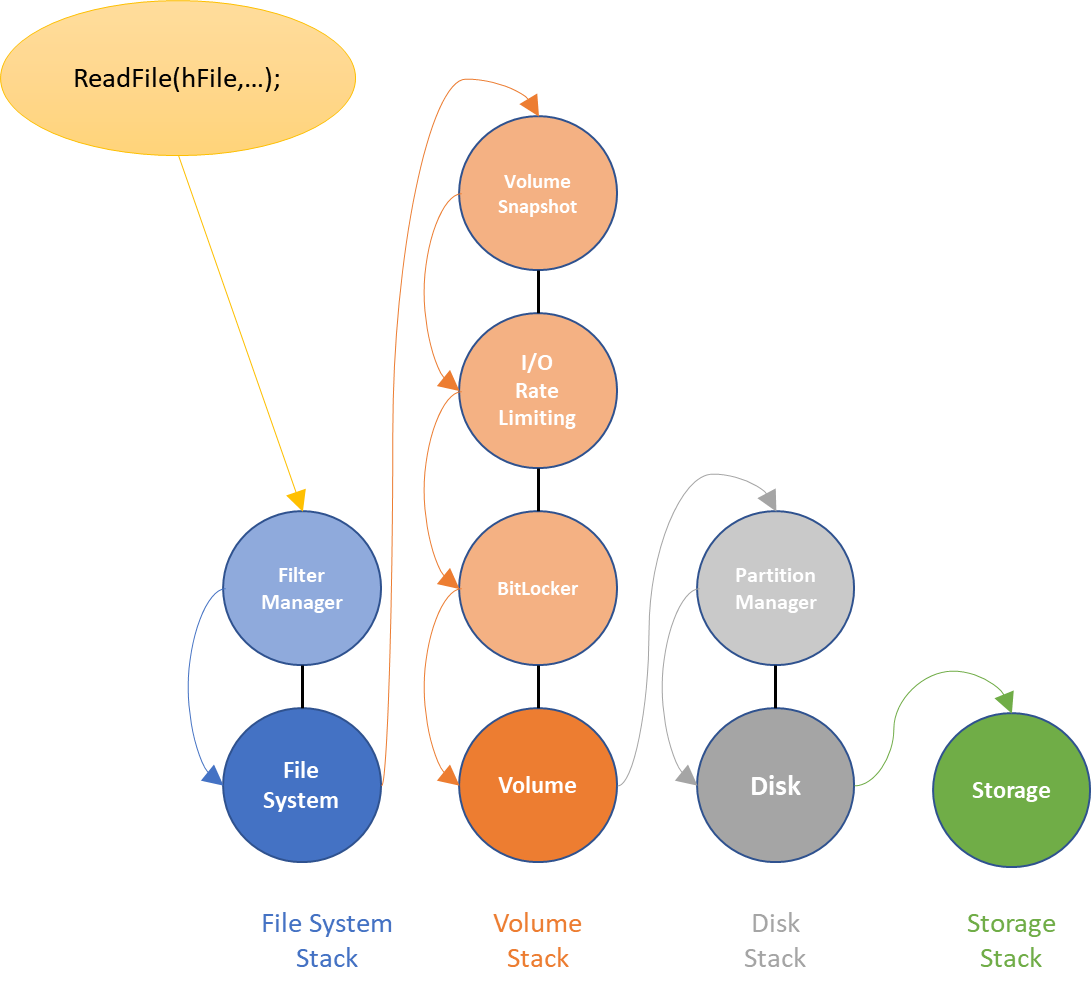
The number of filter drivers present on a default installation of Windows amplifies the issue with the call through model. In order to get an I/O request to the storage adapter, we need to create a call chain that includes eight different drivers!
Legacy File System Filters
Given our discussion thus far, let’s talk about how someone would write a file system filter driver in this model. We call this model the “Legacy” model, because it’s the model that existed prior to the invention of Filter Manager. As part of our discussion, we’ll highlight some different challenges that we might face just in our interactions with the system, let alone in whatever other value add processing we might try to provide (e.g. A/V scanning).
In implementing a file system filter using this Legacy model, we need to get a filter Device Object attached to the file system stack. Once our filter is attached, we’ll see all the I/O requests coming from the application before (“pre-”) the file system (Figure 3).
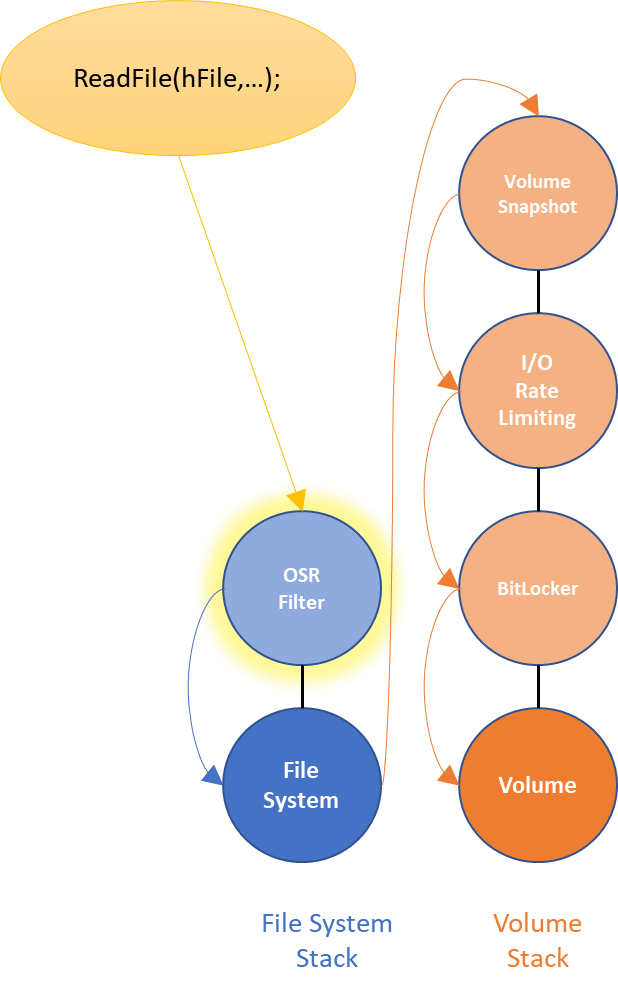
As mentioned previously, the file system filter could also see the operations after (“post-“) the file system’s processing, if it attached it filter Device Object in a different place. But, let’s just deal with “pre-” filtering for now.
Common Problems in Legacy File System Filtering
There are several problems that quickly happen when you talk about putting a filter in the file system stack. We’ll highlight seven specific problems here.
Problem 1: Filter Layering
There is only one file system filter in this figure. However, if there were multiple there is no architecturally defined order for how multiple filters in the stack are layered. The OSR Filter in Figure 3 might be above other filters in the file system stack, or it might be below the other filters. Or it might be above some other filters and below others. The best we can do is try to choose the right load order group for our filter and hope that works well enough.
Problem 2: Dynamic Loading and Unloading
Filter drivers can only be dynamically attached to the top of the Device Stack. For example, I could not take a running system and insert another filter driver between the OSR Filter and NTFS. Additionally, filter drivers cannot dynamically detach from an active Device Stack safely.
The only way to properly layer the filter or detach the filter (and thus unload your driver) is by destroying the Device Stack entirely and rebuilding it with the filter in place. In the case of your system volume, this means instantiating your filter anywhere but at the very top of the Device Stack, or unloading your filter driver, will require a reboot.
Problem 3: Mechanics of Attachment and Detachment
HOW the file system stack instantiates itself and tears itself down is a deep rat hole that’s filled with weird edge cases. Just managing the attachment and detachment of the filter to the stack requires a significant amount of arcane knowledge that no one should need to know (including special case handling for when you eject a floppy diskette and then re-insert it!).
Problem 4: Propagating I/O Request Packets (IRPs)
Once a filter Device Object is attached to the Device Stack, it is responsible for processing all I/O Request Packets sent to the Device Stack. Even if a filter driver is only interested in processing read requests, it still must intercept all requests supported by the lower drivers in the Device Stack.
Problem 5: Trouble with Fast I/O Data Operations
As mentioned earlier, Windows uses a packet based I/O model. For example, each call to ReadFile in user mode creates a new, unique I/O Request Packet (IRP) to represent the I/O operation. The IRP is then passed around from driver to driver until the request is completed.
Long ago, someone made an interesting observation: lots of IRPs only make it as far as the file system before they are completed. This is particularly true in the case of cached file I/O. The file system simply copies the data out of the file system cache and returns it directly to the user. In these cases, all the work to build the IRP and pass it along was wasted.
Thus, the idea of “Fast I/O” was born. The file systems provide something called a Fast I/O Dispatch Table, which contains entry points to, for example, read data from a cached file. Instead of building the IRP, the I/O Manager bypasses the Device Stack entirely and calls directly into the file system to retrieve the data.
Now for the fun part: the I/O Manager always calls the Fast I/O Dispatch Table located at the top of the Device Stack. Once a filter driver is attached at the top, the filter driver receives the Fast I/O requests. If the filter driver does not register a Fast I/O Dispatch Table, then Fast I/O processing is disabled for the Device Stack and we lose the benefit.
Thus, it is the responsibility of the filter driver to “pass” Fast I/O requests down the stack by calling the lower driver’s Fast I/O Dispatch Table. There is no support for this processing provided by the system, thus every driver must invent and provide this code to not lose functionality in the system.
Problem 6: Trouble with Fast I/O Non-Data Operations
You would be foolish to think that the Fast I/O Dispatch Table only contains callbacks related to I/O!
File systems in Windows are deeply integrated with both the Cache Manager and the Memory Manager. This integration is often complex, but getting it right is key to supporting all modes of file access as well as ensuring good file system performance.
To maintain a consistent locking hierarchy between the file system, Cache Manager, and Memory Manager, there are also some callbacks in the Fast I/O Dispatch Table that are related to acquiring locks in the file system. For example, the Memory Manager call’s the file system’s AcquireFileForNtCreateSection callback when a user attempts to memory map a file.
Unlike the Fast I/O callbacks related to data operations, the locking related callbacks are always sent directly to the file system. That is, they are not always sent to the top of the Device Stack. That means your file system filter, attached above the file system in the Device Stack, will not see these Fast I/O callbacks.
Sounds great, right!? Finally something we don’t need to deal with… However, a file system filter might actually be interested in these callbacks. For example, there are many cases when a filter might want to know that an application is memory mapping a file. If the callback bypasses the file system filter and goes directly to the file system, how does the filter get that notification?
On XP and later a mechanism was added: FsRtlRegisterFileSystemFilterCallbacks. This allows the filter to receive notification (and even fail) locking requests related to various Cache and Memory Manager activities. Note that these callbacks do not need to propagate execution to lower filter drivers, the operating system takes care of the layering for us. They also take an entirely unique set of arguments from the standard IRP and Fast I/O based callbacks.
Problem 7: Trouble with Recursion
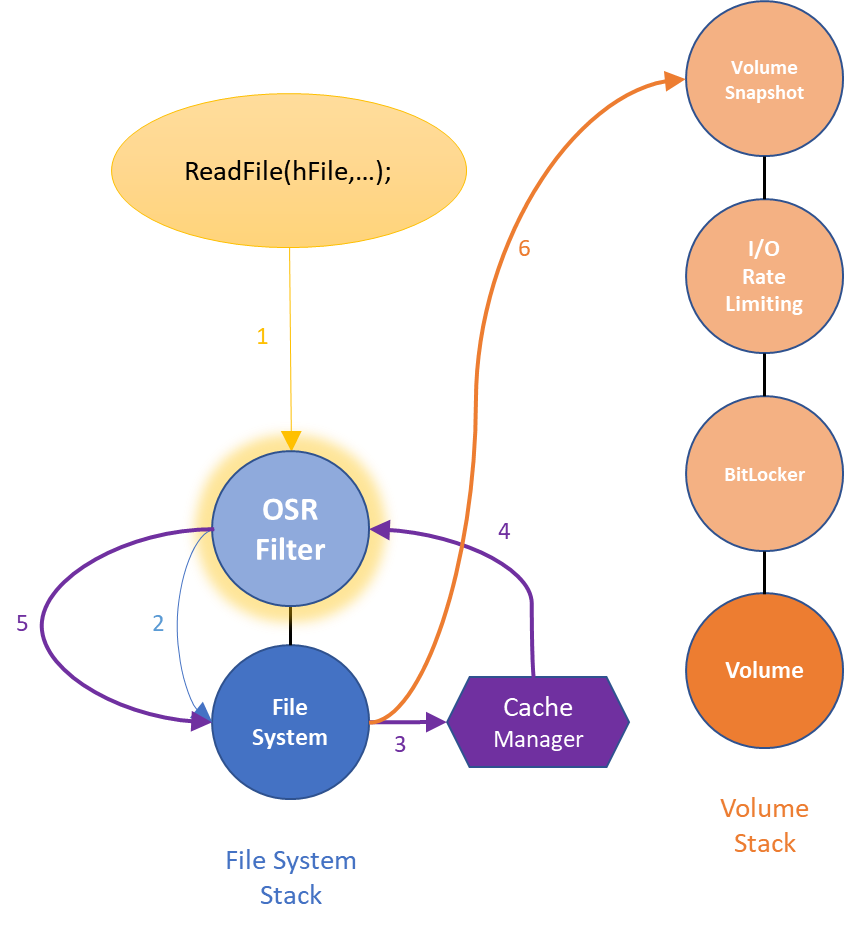
File system operations tend to be recursive by nature. For example, imagine that an application sends an ordinary (cached) read request to the file system. This I/O request will flow down the file system Device Stack (as discussed) before reaching the file system.
The file system will then ask the Cache Manager to please copy the data from the cache into the user data buffer. But, what if the data is not in the cache? The Cache Manager must then perform a non-cached read of the file data to retrieve the data from disk. Of course, it does this by submitting a new read request to the top of the file system Device Stack. Thus, a file system filter may pass a read request down the stack and, before it returns, may see another read request arriving from the same thread (Figure 4).
in the Minifilter World
While recursive operation is a way of life in the file system stack, file system filters can amplify the problems of recursive processing.
First, remember that all this I/O is done using a call through model. Thus, the call stack can be enormous. It was not at all uncommon to see bug checks due to stack exhaustion (stack overflow) when there were multiple legacy file system filters present in a system.
Secondly, if a file system filter generates its own recursive I/O then the filter must take care to avoid deadlocking itself (or other filters). For example, imagine an anti-virus filter that does not want to allow an application to read from a file before that file has been scanned. If the file system filter generates recursive I/O operations to read the file, the A/V scanning filter will see its own read I/O requests arrive at the top of the device stack. It must be sure to allow those reads to occur, even though the file scan has not yet completed.
Problem Summary: A Lot of Work to do Nothing
To give you a sense of scope, old versions of the Windows Driver Kit shipped with a “Simple” legacy file system filter driver. This filter did absolutely nothing except attach a filter Device Object, pass all IRP and Fast I/O requests without modification, and register for the file system filter callbacks. The total line count for this “do nothing” filter? Six thousand eight hundred. 6,800!
Common Tasks in Legacy File System Filters
Now that we have that almost 7,000 lines of boilerplate code in our file system filter, we can get to work! There are lots common things that almost every file system filter driver needs to do. Let’s talk about three of those next.
Common Task 1: Contexts, Contexts, Contexts
One of the things that we will undoubtedly want to do is attach “context” — private, per-instance data — to various different things that our file system filter deals with. For example, we might want to create a context for the underlying file system and volume that we’re filtering. Are we filtering FAT? NTFS? Is the drive removable or fixed? Or are we filtering the network?
We might also want context associated with each of the files we are filtering. For example, in our write request handler how do we know which file is being written?
We might also want context associated with the individual streams of a file. For example, in our write request handler how do we know which stream of the file is being written?
We might also want context associated with the individual opens of a stream. For example, in our write request handler how do we know which open of the stream was used to write the file?
But this sort of context tracking should be pretty easy to implement, right? Well, yes and no. Remember, in kernel-mode we can’t just create a lookup table with std::map. So, you’ll have to roll your own. This means you’ll need to have storage for those contexts. You’ll need to access them in an entirely thread-safe way. You’ll need to know when to tear them down. Basically, it’s just a lot of really annoying code that’s needs writing.
Common Task 2: Retrieving File Names
Of course, if you’re in a file system filter driver then you probably want to know the name of the file being read, written, renamed, deleted, etc.
Unfortunately, something that is seemingly so obviously necessary is a very involved and complicated task. There are unwritten rules on when you can and cannot query the names of a file for fear of a deadlock. The overhead of this activity can also be significant, especially when querying name information over the network.
Also, in the legacy filter model every filter that wants a name must perform its own name query. Thus, we have a very involved and complicated task being performed by every file system filter in the stack.
Common Task 3: Communicating with User Mode
It is not uncommon for a file system filter to work in conjunction with a user mode service. The user mode service might be used simply to send control or configuration information to the driver, or to consume logging activity generated by the driver. In many cases, the user mode service can be used to offload complex processing that is much better suited to user mode development (e.g. binary analysis prior to execution).
Like with tracking contexts, the work of communicating with user-mode isn’t rocket science. You can create your own implementation of the Inverted Call Model: get some IOCTLs from user mode, put them on a cancel-safe queue, and the like. You’ll have to be sure to get the locking right, and handle cancelation for those hanging IOCTLs when the user-mode app closes its handle or exits. So, yes… it’s do-able. But it’s not easy, it’s not quick, and it’s not fun.
Common Task Summary: A Ton of Work to do a Little
Because I love counting lines of code, we’ll look to the old FileSpy sample to get a sense of scope in the leap from “do nothing” to “do the common things you probably need.” The FileSpy sample creates file system and volume context, as well as per-stream contexts. It retrieved file names for individual file operations, and logs file system activity to a user mode console application.
The grand total for the filter only (i.e. not including user mode components): 16,200!
Legacy Filters: A Model that Clearly Needs Fixed
So, there you have the state of Legacy file system filter development before the invention of Filter Manager and Minifilters. The highlights include:
- No ability to dynamically load and unload the filter
- Non-deterministic behavior in terms of the layering of filters
- The simple act of attaching the Device Object to the stack is needlessly complicated
- Increased execution stack utilization for each and every filter added
- Filters intercept requests in three different ways: IRPs, Fast I/O, and File System Filter Callbacks
- When there are multiple filters loaded, there is a significant amount of duplicate work, especially around querying file names
- Filters that generate recursive I/O requests need to perform extra work to avoid blocking their own execution. Filters must also be prepared to handle recursive I/O from lower filters
- Filters need to create their own mechanisms to track per-item context
- Filters that need to communicate with user-mode must create all their own communication code
- A filter that does nothing takes 6,000 lines of code
- A filter that kind of does something takes 16,000 lines of code
This is all in addition to the fact that the Windows file system I/O interface is inherently complicated. Much of this is due to the long history of the interface and the many edge conditions that have been created over the years. As mentioned, there is a significant amount of recursive activity generated by the file system. During these recursive I/O operations, locks may be held by the lower file system, thus making it dangerous to attempt incompatible operations. And, as mentioned, the file systems are deeply integrated with the Cache and Memory Manager subsystems in Windows, which have their own rules and own locking requirements.
Lastly, each Windows file system is different than the other by way of implementation. Thus, the behavior that you see while interacting with a particular file system may be architecturally similar but different in its observed behavior.
Taken together, this was why a group of very senior file system and kernel architects and developers at Microsoft (i.e. “very smart people”) decided this needed fixed. Not because they had nothing better to do, but because a large percentage of Windows crashes were being blamed on file system filter drivers. While you could try to blame the filter developers for this, the filtering model was objectively broken. File system filter drivers were clearly an afterthought in the original design of NT. And they just required way too much grunt work to implement; Work that was often tricky and easily prone to bugs. It was time to sit down and architect a “better way” to write a file system filter driver on Windows.
Enter Filter Manager
And this is where Filter Manager, the Filter Manager Framework, and File System Minifilters enter the picture. The team behind Filter Manager wanted to make it easier and more reliable to write a file system filter driver on Windows. In doing so, there were two significant requirements that had to be met:
- The “new” way to write a file system filter must be as flexible as the existing model. If there was a filter type that could be written the old way, but not in the new way, then the new way was a failure.
- The underlying file system architecture in Windows could not be radically changed. In other words, the goal of simplifying file system filter development could not be met by simplifying the file system interface. Remember this point, especially, because we’re going to return to it later.
Thus, the ultimate solution to the problem was to create a comprehensive “framework” for writing file system filter drivers. The framework provides the one legacy file system filter driver necessary in the system, and consumers of the framework plug in as “Minifilters”. This single legacy filter would be serve as a universal file system Filter Manager. As I/O requests arrive at the Filter Manager legacy filter Device Object, Filter Manager calls the Minifilters using a call out model. After each Minifilter processes the request, Filter Manager then calls through to the next Device Object in the Device Stack (Figure 5).
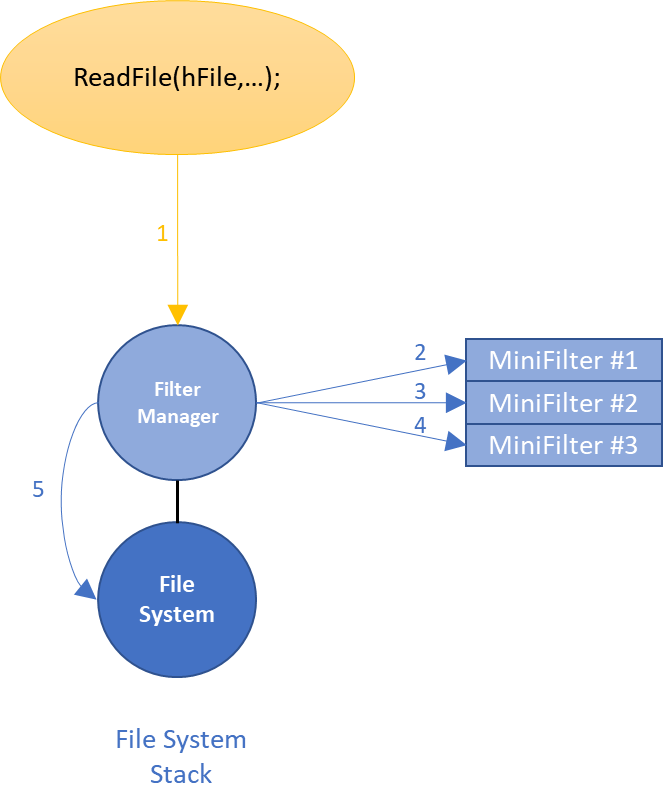
However, Filter Manager does not simply pass the native operating system operations to the Minifilters. Instead, Filter Manager creates its own abstractions of the native operations (we’ll see the benefit of this shortly).
What Filter Manager Does
Filter Manager is great and does a lot of things for you. This includes but is not limited to the following.
Filter Manager: Allows for Dynamic Load and Unload
Filter Manager itself is a legacy file system filter driver, thus it cannot dynamically load and unload. However, it provides support so that minifilters can dynamically load and unload (if they choose).
Filter Manager: Provides Deterministic Layering Behavior
Filter Manager introduces the concept of altitudes, where higher altitude filters are called before lower altitude filters for operations en route to the file system. Altitudes are groups by functionality (e.g. AntiVirus, Encryption, etc.) and Filter Manager ensures that the filters are called in the correct order based on their altitudes.
Filter Manager: Simplifies Filter Attachment
Filter Manager still needs to deal with all those annoying details of how the file system stack instantiates and tears down. However, it does not expose the minifilter driver writer to all this non-sense. Instead, Filter Manager creates an abstraction called an Instance. An Instance is an instantiation of a minifilter within a file system stack (e.g., in Figure 5 there are three Instances). Instance setup and teardown follows a sane set of rules and requires minimal code (and no special case floppy code!).
As an added bonus, a single filter is even allowed to have multiple instances within the same stack! This has some useful applications, including breaking a complex filter up into multiple different instances. For example, in our File Encryption Solution Framework (FESF) we use separate instances for data transformation (i.e. encryption) and managing the on disk structure of our encrypted files.
Filter Manager: Dramatically Decreases Stack Utilization
Filter Manager’s use of a call out model to the minifilters significantly decreases the stack utilization of I/O operations. It also means that adding more filters does not instantly increase the stack utilization of every single I/O request.
Filter Manager: Provides a Standardized Context Model
As mentioned previously, file system filter drivers universally need to attach context to things such as volumes, files, streams, and even File Objects (i.e., open instances of files or streams). Filter Manager provides a consistent context API for attaching and retrieving context for these objects. Filter Manager also provides additional support for attaching context to instances, transactions, and memory mappings.
Filter Manager: Provides a Unified Callback Model
Legacy file system filters needed to deal with IRPs, Fast I/O, and FsRtl filter callbacks to capture all possible file system operations. Filter Manager rationalizes all these different callbacks into a single, unified callback using a Callback Data structure. This Callback Data structure provides a consistent view of file system operations and is the one structure that Minifilters need to understand to filter any file system operation.
Filter Manager: Provides Name Query Support (with Cross-Instance Caching)
Filter Manager provides a consistent interface for querying file names for any given file system operation. In addition, Filter Manager understands all the situations in which it is not safe for a file system filter to query name information. So, instead of a difficult to diagnose deadlock in your filter, Filter Manager simply returns an error if it is currently unsafe for you to query name information.
Even better that the above: Filter Manager caches the results of name query operations and shares the results amongst Minifilter instances. Thus, if one filter queries the name for a given I/O request, other filters can benefit from the cached result.
Filter Manager: Supports for Avoiding Recursive I/O
Filter Manager allows Minifilters to target I/O requests at specific altitudes. Thus, a Minifilter can choose to send an I/O request only to those Minifilters that are at lower altitudes. This means that a Minifilter does not need to write defensive code to detect its own recursive operations.
Filter Manager: Provides Built-In Methods for User/Kernel Communication
Given that the majority of file system filter drivers communicate with user mode, Filter Manager provides a nice Communication Port package for bi-directional communication. User mode applications can easily send messages to the minifilter, and the minifilter can easily send messages to user mode (with or without a response).
Filter Manager: Dramatically Decreases the Size and Complexity of Boilerplate Code
Clearly a major goal in the creation of Filter Manager was to reduce the amount of boilerplate code in a filter. If every Minifilter needs complex attachment code, then Filter Manager should handle that. If every Minifilter is going to perform name queries, then Filter Manager should handle that. If every Minifilter is going to communicate with user mode, then Filter Manager should handle that.
So… File System Filters are Now Simple To Write!?
Filter Manager is so well considered and so well executed, that it almost makes writing filters easy! A simple sample Minifilter is only about 900 lines of code (mostly comments) and there are lots of examples provided on GitHub. It’s all very approachable and, in fact, quite easy to get something demonstrably working in a short period of time.
If there’s one criticism if Filter Manager, it’s that while it makes implementing a file system Minifilter pretty easy, it doesn’t do anything to change or hide the complexity of the Windows file system architecture. This is due to the second of the two primary goals for developing Filter Manager that we described earlier: The underlying file system architecture in Windows could not be radically changed.
So, the mechanics of file system filtering are now much easier thanks to Filter Manager. But the overall Windows file system architecture is still complex, often subtle, and can even be downright arcane at times. Not only can the semantics of certain file system operations sometimes be confusing and/or obscure, but the file system’s close integration with the Cache Manager and Memory Manager can cause serious headaches.
As a quick example of something that sounds like it should be easy in file systems, but often takes new Windows file system devs by surprise, is how delete operations are handled. Most folks think this can’t be complicated. After all, to delete a file in Windows you just call the Win32 function DeleteFile. Don’t you? Well, yes. That’s correct. But Windows file systems don’t directly implement the Win32 API. A call to the Win32 DeleteFile function actually becomes a call to NtSetFileInformation, with the FileInformationClass set to either FileDispositionInformation or FileDispositionInformationEx. By the way, there are more than seventy FileInformationClass codes defined, and — as of today at least — only two of them involve delete. Choosing just one of the delete-related class codes to look at further, the FileDispositionInformationEx class requires passing a FILE_DISPOSITION_INFOMRATION_EX structure that defines six flag values, some of which are complementary and some of which are mutually exclusive. Taken together, these flag values indicate whether the file should be deleted. And, lest you think that — having decoded this structure — this operation actually immediately deletes the file, it does not. It just indicates that the file should be deleted when it’s eventually closed. That is, if nobody else marks the file to not be deleted (using NtSetFileInformation, of course) before it’s eventually closed.
Now, I’m not saying that’s the most complex or obscure file operation that you could possibly imagine. But, that’s delete for goodness sakes! To most folks, that very basic operation just doesn’t sound like it should be anything but straight forward. But, Windows file system semantics are seldom straight forward.
The net result of all this is that it’s easy, safe, and even relatively pleasant to write simple file system filters using Filter Manager. If you want to write a Minifilter that monitors access to certain files that is pretty easy. But, if you want to do anything beyond mere passive monitoring, things can get complex, and that complexity and sneak-up on you very quickly.
In Summary
In this article, we’ve seen how filtering works, architecturally, in the Windows I/O Subsystem in general and for file systems in particular. We reviewed the problems and common tasks that legacy file system filters had to deal with. These problems and common tasks illustrated the primary motivations for developing the Windows Filter Manager Minifilter model for file system filtering.
We also described how Filter Manager meets the needs of Windows file system filter developers, and makes their jobs much easier.
Finally, we concluded our discussion with a warning that, while Filter Manager makes the mechanics of implementing a file system filter driver much easier than it was in the past, it does nothing to remove the inherent complexity of Windows file system operations. And Windows file system operations can indeed be surprisingly, and often unexpectedly, complex.
