
I have long held that C++ sucks, and that it sucks really, really, badly. I have been so very vocal about this over the past 20 or so years, that almost anyone who’s been involved in Windows driver development and has read NTDEV even a little has seen me hold forth on this topic.
I am not alone in this belief. In fact, no lesser beings than Mr. Penguin Pants and Elon Musk agree with me. Ken Thompson and Rob Pike apparently also agree.

But… I like to think that I’ve changed some over the years. And over time C++ has very much changed. Versions of C++ before C++ 11 are very different from versions of C++ since. We now have a type of C++ that’s generally referred to as “Modern C++” – If you’re new to this concept, there’s quite a nice description on MSDN.
I have, somewhat reluctantly due to the extreme level of my previous vociferousness, concluded that maybe there are some features of Modern C++ that aren’t so bad. In fact, I think there are some features that even the most enthusiastic C Language programmer might find both useful and (more importantly) helpful in building quality into Windows drivers.
In this article, I’ll describe a few of the C++ features that we regularly use at OSR in driver development. You’ll see we’re not entirely “bought in” to the world of C++; But, as C++ has evolved and we’ve evolved, we’ve come a long way from our previous position which was “If you put any C++ code in one of our drivers, you will be hanged, drawn and quartered.”
Limitations on C++ in Windows Drivers
Before we begin, I should probably note that there are many good and useful things in Modern C++ that cannot be used in kernel-mode. This is because in Windows kernel-mode does not support C++ exception handling. C++ exception handling is entirely different from our customary kernel-mode Structured Exception Handling. As a result of this limitation, most parts of the C++ Standard Library (std) are off limits, including some of the most pleasant and useful features such as Containers (std::vector, for example) and string handling. This also means that you can’t use ATL or STL – both of which are pretty much superseded by std anyhow. Unless, that is, you’re using ATL for writing COM programs. And if you are, well… I’m sorry.
So, having mentioned some cool stuff that we can’t use, let’s have a look at five of our favorite C++ constructs that do work in Windows kernel-mode drivers.
#1: Strong Type Checking
Yes, I realize that this isn’t a Modern C++ innovation. But it’s still a massive advantage of C++ over plain old C. There can be little disagreement that strong type checking, which is inherent in C++, is a good thing. Over the past million or so years that I’ve been in this business, I’ve inherited numerous drivers that were initially written (usually by clients) in “pure” C. And I can truthfully say that I have never, not once, failed to find a meaningful type error when I’ve renamed those files with CPP extensions and rebuilt them. I think that’s a good enough argument for strong type checking’s value.
#2: constexpr instead of #define
I hope there’s nobody left in the world who doesn’t think that the use of preprocessor macros in C/C++ is, at best, “problematic.” By way of review: Good old #define performs a textual substitution at compile time. This can lead to all sorts of unintentional problems, given that there’s no type safety in a #define, arguments passed into the #define can get evaluated multiple times, and more. I’m not saying you should never use #define. I’m just saying you should use it when no other tool in your toolbox will do.
Usually constexpr can be used as a direct replacement for “simple” #defines, such as when you define bitmasks and register bit patterns. The primary difference in this case is that constexpr has a type. Visual Studio will even suggest that you change your basic #defines to constexpr and will offer to do the conversion for you (Figure 1).
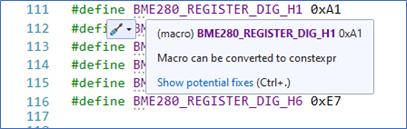
The only disadvantage I see to letting VS have its way with your code here, is that it uses auto for the type… which may not be what you want (Figure 2).
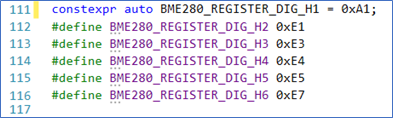
I, personally, much prefer to specify the type myself. After all, I know how/when/where I’m going to use the definition (Figure 3).
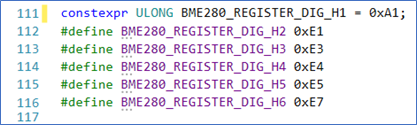
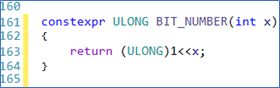
You can/should also use constexpr in place of many of your “function like” #define macros. For example, the classic macro shown in Figure 4, is quite easily converted to a constexpr. This lets you replace the macro with the equivalent of a function, the result of which is available at compile time. Though VS won’t suggest this conversion with cute little dots, it will do the conversion for you if you ask it to. It will go out of its way to use type auto, including templating the data types of any arguments – picture me rolling my eyes here. I say just assign the arguments a specific type and be done with it (Figure 5). Let’s agree to delay our argument about whether and when auto is a good or bad thing until later in this article.

#3: Range-based “for” Loops
This is a feature that I don’t use every day, but when I do have use for it I wonder “where has this been all my life.” I love the range-based for loop.
Consider the following chunk-o-code, ignoring (please) whether this particular character-by-character search is wise and that it doesn’t actually do anything… it’s an example, in an article, after all):
constexpr int MAX_STRING_SIZE = 55;
WCHAR stringBuffer[MAX_STRING_SIZE];
// Later in the code…
for(int i = 0; i< MAX_STRING_SIZE; i++) {
if(stringBuffer[i] == L'\\') {
break;
}
}
Even this code, as shown above, is way better than the way I normally see such code written… which is without MAX_STRING_SIZE and instead with the magic literal constant value “55” used multiple times. Ugh.
Anyhow… it’s bug-prone and annoying to keep (even) the symbolic constants aligned. Assuming your storage definitions aren’t immediately adjacent to your use of that storage, you have to jump back and forth between the declaration and the for loop. “Was the size of stringBuffer MAX_STRING_SIZE or was it MAX_BUFFER_SIZE or MAX_STRING_STORAGE?” When you’re cranking through code, these are the kinds of things that lead to errors. We’ve all seen it.
To avoid dealing with any of this nonsense, we can use a range-based for loop. Like this:
constexpr int MAX_STRING_SIZE = 55;
WCHAR stringBuffer[MAX_STRING_SIZE];
// Later in the code…
for (WCHAR thisChar : stringBuffer) {
if(thisChar == L'\\') {
break;
}
}
My goodness! Isn’t that much more tidy and pleasant?? I think so. The compiler knows the size of the array stringBuffer and with a range-based for, we let the compiler deal with it for us. As a result, when you decide to change the size of the string buffer, you only have to… change the size of the string buffer. And the code takes care of itself. It’s not based on using the right definition. And there’s no chance of getting the definition wrong in the code.
#4: Limited Use of auto
I’m an extreme fan of coding with clarity, simplicity, and ease of maintenance. I dislike code that’s “clever”; I tend to over-document, sometimes to the point of “writing my C a second time in English” (which I readily admit is unwise, but I’m still in recovery from this affliction). Anyhow, my desire for clarity means that I naturally tend to avoid things like auto in most places where you’re supposed to be smart enough to intuit the type of a variable. So, for example, while most Modern C++ fans would probably have coded the range-based for above:
for (auto thisChar : stringBuffer) {
I almost always opt for being specific and clear:
for (WCHAR thisChar : stringBuffer) {
There is one case where I love the use of auto, however. And that’s in assignments where there’s a (big friggin’) cast on the right hand side. For example, consider the following common case where we cast WDFCONTEXT to a Context for a WDFDEVICE in an I/O Completion Routine:
VOID
BasicUsbEvtRequestReadCompletionRoutine(WDFREQUEST Request,
WDFIOTARGET Target,
PWDF_REQUEST_COMPLETION_PARAMS Params,
WDFCONTEXT Context)
{
PBASICUSB_DEVICE_CONTEXT devContext = (PBASICUSB_DEVICE_CONTEXT)Context;
// rest of completion routine..
I don’t see that having the data type fully specified on the left AND the right of the combined declaration and assignment statement to be even remotely instructive. In this case, I save myself some typing by doing the following:
VOID
BasicUsbEvtRequestReadCompletionRoutine(WDFREQUEST Request,
WDFIOTARGET Target,
PWDF_REQUEST_COMPLETION_PARAMS Params,
WDFCONTEXT Context)
{
auto * devContext = (PBASICUSB_DEVICE_CONTEXT)Context;
// rest of completion routine..
Notice, by the way, that I used “auto *” above, even though auto alone would work fine. Call me obsessive, but I like to be completely clear that it is a pointer that I’m declaring. Plus, clang-tidy told me I should do probably this, and who am I to argue? That’s a topic we’ll leave for another article, actually.
#5: Some RAII Patterns
Let’s just ignore what the letters RAII stand for, shall we? RAII patterns are those that do automatic initialization when an object (such as a class) is instantiated, and automatic tear-down when the object is no longer needed. Now, C people, don’t worry… I’m not going to get all OOP on you here. At least, not very much.
I tend to use RAII patterns in my drivers when I have reasonably complex initialization I want to perform and that initialization cannot fail and/or when I have some specific or complex tear-down I need done when I’m done with the object.
Let me give you an example, taken from one of our projects, to illustrate where I find RAII patterns particularly helpful. We have a driver that needs to check the access of a user that’s sent us a Request. This involves acquiring the SECURITY_SUBJECT_CONTEXT, locking it, doing the checks, and then (before exiting the function) unlocking and releasing the SECURITY_SUBJECT_CONTEXT.
It’s a fairly long function in which we need to do this check, and there are numerous things that can cause us to exit from the function prematurely. The code was a complete mess. That is, until I created an RAII class that acquired and locked the SECURITY_SUBJECT_CONTEXT on instantiation, and then automatically unlocked and released it at function exit. You can see the code for the class in Figure 6 below.
class OSRAuthSecurityContext
{
public:
SECURITY_SUBJECT_CONTEXT SubjectContext{};
PEPROCESS Process;
PACCESS_TOKEN PrimaryToken;
explicit
OSRAuthSecurityContext(const WDFREQUEST & Request)
{
PIRP irp;
irp = WdfRequestWdmGetIrp(Request);
Process = IoGetRequestorProcess(irp);
if (Process == nullptr) {
Process = IoGetCurrentProcess();
}
SeCaptureSubjectContextEx(nullptr,
Process,
&SubjectContext);
SeLockSubjectContext(&SubjectContext);
PrimaryToken = SubjectContext.PrimaryToken;
}
~OSRAuthSecurityContext()
{
SeUnlockSubjectContext(&SubjectContext);
SeReleaseSubjectContext(&SubjectContext);
}
//
// Sigh... the Rule of Five requires these
//
OSRAuthSecurityContext(const OSRAuthSecurityContext&) = delete; // copy constructor
OSRAuthSecurityContext & operator=(const OSRAuthSecurityContext&) = delete; // copy assignment
OSRAuthSecurityContext(OSRAuthSecurityContext&&) = delete; // move constructor
OSRAuthSecurityContext & operator=(OSRAuthSecurityContext&&) = delete; // move assignment
};
Figure 6 – An RAII class for SUBJECT_SECURITY_CONTEXT
To take advantage of this RAII object, all we need to do is create an instance on the stack, like you see in Figure 7. Then you can use the class like you’d expect.

Now, for sure, there’s nothing in this so far that you couldn’t have accomplished with a helper function that takes (or returns) a pointer to some sort of “security context” structure and initializes it using the passed-in Request. The magic comes at function exit, shown in Figure 8.
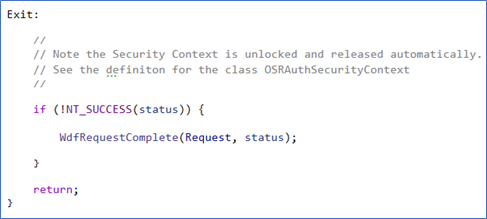
At the end of the function in which our OSRAuthSecurity Context is used, the tear-down is done automatically by the object’s destructor. So, the security context is always properly unlocked and released. There’s no chance of a leak. Our only problem is that we need to be sure we document that this is what’s going on, for the potentially unsuspecting maintainers that come after us.
I don’t know about you, but I call that both “wonderful” and “magic.” Again, it’s not something I need to do in every driver I write. But when I need it, it’s nice to have the feature available.
#6 (Free Bonus!): Default Arguments
I promised you five features to try. But, since I started with one (strong type checking) that is pretty well-known and non-controversial, I’ll give you one, last, extra-special bonus feature: default arguments.
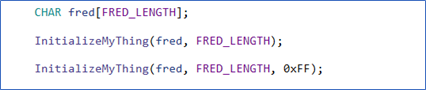
Default arguments can make coding certain functions very easy. Take the example shown in Figure 9. Again, please set aside your judgment as to whether this is a function you’d really want to put in your code… it’s just an example.

In Figure 9, we have a function that takes three parameters. The last parameter, CharacterToUse, is optional. If it’s not supplied when the function is called, a default value (0x00 in the example) will be used. And you can then invoke this function with, or without, that final optional argument as shown in Figure 10.
Most Modern C++ features (like the vast majority of the C++ Standard Library) are primarily applicable to user-mode code. But I hope you’ve seen here that there are a few Modern C++ features than can make your coding life easier, and perhaps even make your drivers more reliable.
It’s worth noting that there are plenty of other C++ features that I like and that work in drivers that I haven’t mentioned. For example unique_ptr, std::tuple, many of the functions in <algorithm>, and perhaps even some uses of lambda expressions. And I dream of someday being able to use std::vector and std::map.
I hope you’ll try some of these C++ features that are new to you in driver projects of your own. If you do, head over to NTDEV and tell us about your experience.
OSR thanks C/C++ expert Giovanni Dicanio for taking the time to tech-review this article so that we didn’t expose ourselves as C++ dilletantes. You can catch up with Gio via his blog at https://blogs.msmvps.com/gdicanio/. Gio is an author of several excellent C/C++ related courses that you can find on Pluralsight. Don’t forget that if you have an MSVC subscription, you probably also get free access to Pluralsight courses!
Updates: 29 October. Thanks to the report of an observant reader, we fixed two spelling mistakes including the unintentional capitalization of “explicit” and a reference to std::algorithm, which should of course be <algorithm>.
